
Яна ЛеКуна называют одним из крестных отцов искусственного интеллекта. В конце 80-х он вместе с двумя другими учеными — Джеффри Хинтоном и Йошуа Бенжио разработал концепцию свёрточных нейронных сетей. Сегодня это стандарт для распознавания и обработки изображений. Они используются для обнаружения объектов, медицинской диагностики, распознавания лиц, анализа видео и многих других задач.
Ян занимает в Meta должность главного научного сотрудника по ИИ. Своей главной целью он считает создание нового типа искусственного интеллекта, который сравнится с человеческим и будет рассуждать и понимать мир так, как это делают люди и животные. О том, как к этому прийти, сравняется ли искусственный интеллект с человеческим и чего действительно стоит бояться, он рассказал на конференции AI for Good в Женеве. Я записал самые интересные моменты из его выступления.
Содержание
- 1 LLM в текущем виде — тупик развития ИИ
- 2 ИИ нового поколения будет рассуждать абстрактно, а не пытаться угадать следующее слово
- 3 Опасен ли такой ИИ?
- 4 Будущее ИИ — в открытом коде
- 5 ИИ должен усиливать, а не заменять человека
LLM в текущем виде — тупик развития ИИ

Если вы заинтересованы в создании сверх интеллекта или в том, чтобы ИИ сравнялся с человеческим интеллектом, то большие языковые модели (LLM) — это тупик. Это не означает, что LLM бесполезны, но если мы хотим достичь большего, то нам придется изобрести новые методы и новую архитектуру.
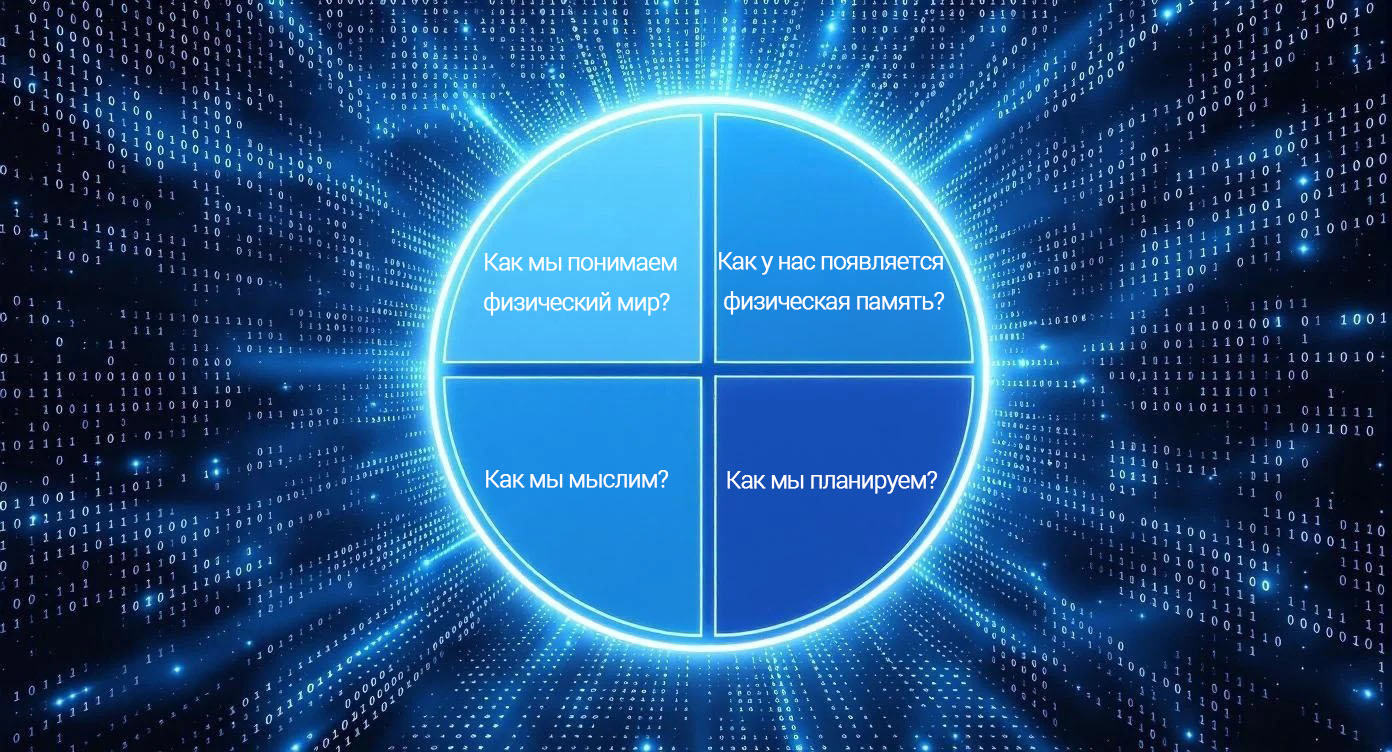
Попробуем задать четыре вопроса. Как мы понимаем физический мир? Как у нас появляется постоянная память? Как мы рассуждаем? Как мы планируем?
Эти четыре сущности лежат в основе интеллекта. Ни одна из существующих сегодня LLM не способна планировать, делать выводы на нужном уровне, да и вообще не обладает такими фундаментальными возможностями как люди.
Когда-нибудь мы научимся создавать системы, которые превзойдут человеческий интеллект в большинстве сфер, и я надеюсь, что это произойдет в течение следующего десятилетия. Для этого нам нужно решить две принципиально важные задачи.
Первая — это тип генерации ответа на запрос пользователя — инференс. В процессе рассуждения LLM проходит через фиксированное количество слоев нейросети и в конце выдает ответ, он же токен. Количество вычислений, которое LLM может выполнить для выработки ответа, — фиксировано. И это проблема.
LLM тратит одинаковое количество итераций на поиск ответа на простой вопрос, где достаточно сказать «да» или «нет», и на сложный, где нужно думать глубже. И это бессмысленно. Ведь на простой вопрос можно ответить сразу, а на более сложный у людей включается процесс размышления.
Во время рассуждения люди в голове прокручивают возможные сценарии развития событий, и у них нет необходимости что-то записывать, за исключением, например, математики или программирования. В большинстве случаев мы рассуждаем, планируем, принимаем решения, используя абстрактную модель происходящего в уме — все то, что психологи называют мышлением второго типа.
Сейчас искусственный интеллект вычисляет ответ, а мы стремимся к тому, чтобы он научился долго думать и искать его. Это принципиально другой процесс.
Вторая важная вещь: ИИ надо «заземлить» в нашей реальности. Не обязательно физической — она может быть виртуальной, но должна быть какая-то база, откуда AI получает информацию с большей пропускной способностью, чем просто текст. Человек получает огромный объем информации через зрение, слух, осязание.
СпецпроектыНе чекає, поки спрацює правило, а самостійно шукає відхилення. Як Elastic AI захищає від кіберзагрозBitget запускає токенізовані акції в партнерстві з xStocks
Четырехлетний ребенок уже знает столько же, сколько LLM, обученный на всех доступных текстах в интернете. Мы не дойдем до человеческого уровня AI, если не дадим системам понять реальный мир.
ИИ нового поколения будет рассуждать абстрактно, а не пытаться угадать следующее слово
Мы подходим к основной проблеме — несовершенство современных архитектур. Современные LLM тренируются предсказывать следующий токен, то есть подбирать отдельные фрагменты текста один за другим, а не моделировать окружающую действительность, как это делают люди.
Чтобы система понимала мир, нужна новая архитектура. Я выступаю за JEPA — Joint Embedded Predictive Architecture. Это система, которая в корне отличается от LLM. В этой новой системе LLM все равно будут играть свою роль, ведь они прекрасно превращают наши мысли в связный и понятный текст.
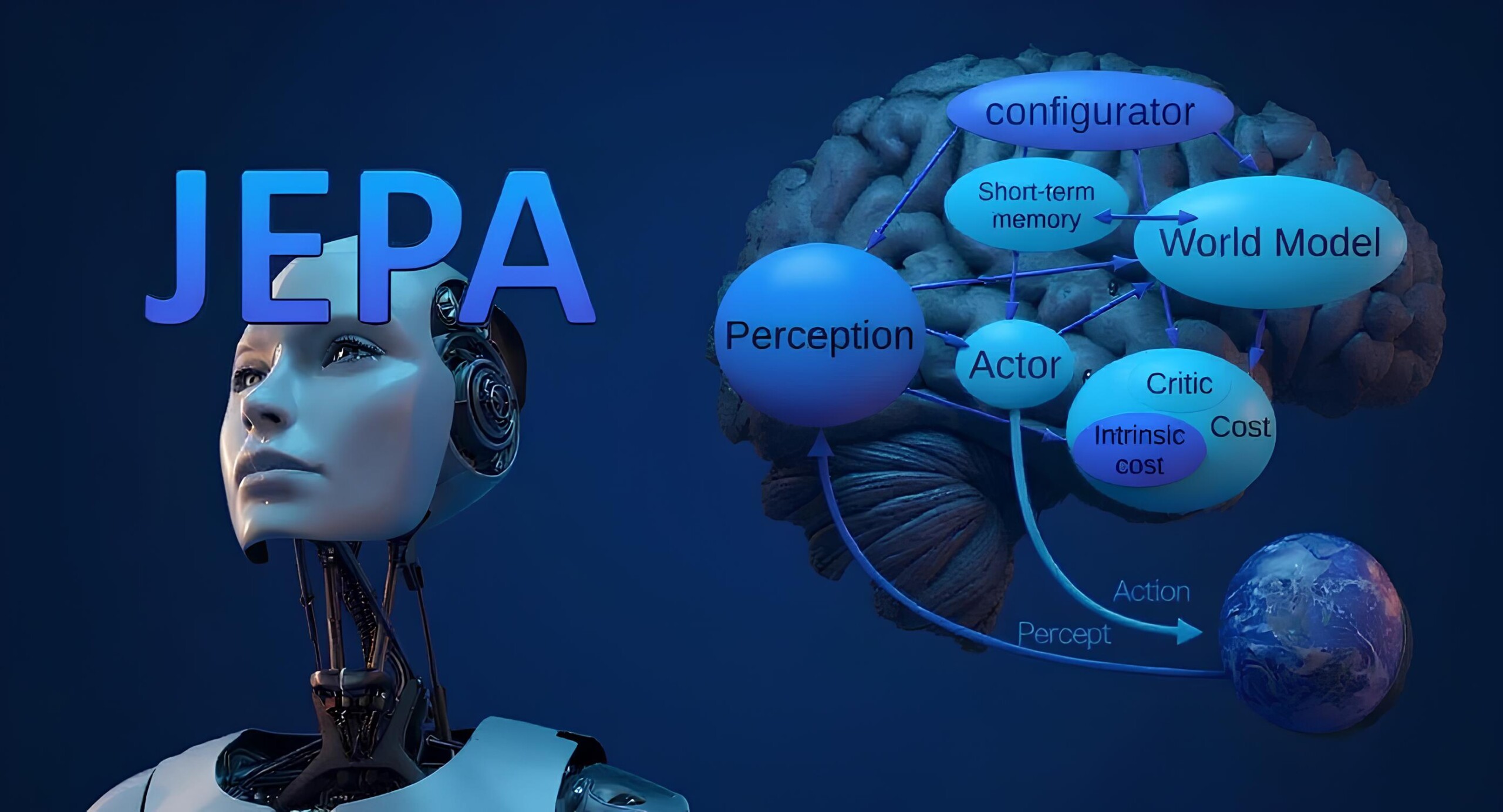
Но JEPA — это не LLM, это совсем другая сущность.
Многим это может показаться странным, но язык — это относительно простая вещь, потому что он дискретен: в нем ограниченное количество слов, и не так сложно угадать, какое будет следующее — что и делают LLM. Но реальный мир гораздо сложнее. Если показать LLM видео конференц-зала и попросить ее предсказать, что произойдет дальше, она запутается.
Невозможно угадать каждую деталь, вроде того, как выглядит каждый человек в зале или какого цвета ковер Идея JEPA заключается в том, чтобы предсказывать не токены, а абстрактные представления. Она оперирует высшим уровнем абстракции, игнорируя детали, которые невозможно предсказать. Благодаря этому получается модель, которая лучше понимает, что происходит.
Опасен ли такой ИИ?

Когда мы разберемся, как выйти на уровень ИИ, близкий к человеческому, это не станет квантовым скачком — мы пройдем через уровни разума, как у крыс, кошек, собак и так далее. У нас будет время сделать такие системы безопасными. ИИ будущего — objective-driven, он будет работать на достижение четко поставленной цели, и с «ограничителями», которые система не сможет нарушить. У нынешних LLM другая суть работы, цель задается пользователем в промпте — и это очень слабая спецификация, полностью зависящая от того, как и чему обучали эту LLM.
В новой архитектуре цель прописана изначально, и система не может делать ничего, кроме как решать задачу пользователя в рамках заданных ограничений. Осталось понять, как правильно формулировать эти цели и ограничения — задача сложная, но не невыполнимая. Вероятность, что такая система навредит, примерно такая же, как вероятность взрыва следующего самолета, на котором вы полетите, — крайне мала, потому что проектированием занимаются профессионалы, которые десятилетиями совершенствуют системы безопасности.
Это не значит, что надо взять и зарегулировать ИИ полностью. ИИ, который применяется для медицинской диагностики или помощи водителю, проходит испытания и проверки, получает одобрение госорганов — все как в авиации. Для чат-ботов такого регулирования нет, потому что риски малы, и серьезного вреда за два года их массового использования не произошло.
Будущее ИИ — в открытом коде
Моя роль в Meta — исследования и долгосрочная стратегия. Моя работа — вдохновлять, продвигать идеи, вроде JEPA. Именно FAIR, исследовательское подразделение Meta, выложил Llama в открытый доступ, как и множество других наработок — более тысячи проектов за 11 лет.
Я верю в то, что ИИ должен строиться на основе систем с открытым кодом. Исторически сложилось так, что платформы с открытым кодом — безопаснее, надежнее, гибче. Так работают интернет, мобильные сети. Больше глаз — быстрее исправляются ошибки. Для ИИ это особенно важно: невозможно проверить безопасность системы, если ты не можешь ее модифицировать и тестировать.
По моему мнению, самая большая опасность сегодня — это не риски, что ИИ сделает что-то не так, а то, что все наши цифровые взаимодействия будут проходить через один или два «закрытых» ИИ-агентов, и вы будете получать всю информацию из пары источников. Уже сейчас многое из нашего цифрового потребления — это результат работы машинного обучения: не очень умного, но они пишут, фильтруют, модерируют огромное количество контента.
В будущем весь наш цифровой рацион будет поступать от ИИ-систем.
Поэтому нам нужно многообразие ИИ-ассистентов с разными языками, культурными ценностями, политическими взглядами. Это можно сравнить с прессой: если у нас только один монополист — это плохо для общества. Да и многие страны не примут угрозу того, что вся информация будет поступать, например, из США или Китая. Открытый код — единственный способ обеспечить такое разнообразие.
Иногда звучат предложения, что, мол, open-source — это плохо, вот посмотрите, китайский DeepSeek учился на Llama. Можно подумать: «А вдруг закрыть разработки на Западе и замедлить распространение идей, чтобы конкуренты отстали?».
Но они все равно узнают, только с задержкой. Проблема в том, что мы будем медленнее двигаться сами, сами себя будем тормозить. Это как стрелять себе в ногу. Надо быть лучшими в умении брать новые идеи и внедрять их. К тому же мы, в свою очередь, учились у DeepSeek и других моделей, в том числе и у китайских коллег, которые активно выкладывают свои модели в открытый доступ.
Даже если полностью изолировать Китай интеллектуально, у них все равно отличные инженеры и ученые, и они быстро догонят, а возможно, даже обгонят Запад. Пример DeepSeek стал шоком для многих в Калифорнии.
ИИ должен усиливать, а не заменять человека
В будущем, думаю, ситуация будет похожа на современный рынок операционных систем: 2-3 доминирующие платформы, среди которых одна-две будут открытыми, плюс еще пара-тройка закрытых и нишевых для спецзадач. Я так считаю, потому что вижу будущее, в котором LLM и то, что за ними последует, станут хранилищем всего человеческого знания и культуры. Чтобы это реализовать, им понадобится доступ к данным со всего мира, из разных стран и регионов.

Но страны не готовы делиться данными просто так — им нужен ИИ-суверенитет, то есть контроль над собственными данными и над тем, как на них учится и работает искусственный интеллект.
Поэтому единственный выход — международное партнерство, при котором будущие модели будут обучаться распределенно, обмениваясь не данными, а параметрами моделей. Так получится общая консенсус-модель без потери каждой страной суверенитета над своими данными. И это обязательно должен быть открытый исходный код.


{kind=link}